Fine-tuning DeepSeek-R1 on Bhagvad Gita text chunks using Glows-AI GPUs

In this article, I’ll discuss how to use the GPU service provided by Glows.ai. It is not advisable to refer to this fine-tuning pipeline for educational purposes. This article is solely about how to get started with Glows.ai GPUs and how you can have your own Jupyter Lab workspace, which runs their GPU in the background.
Dataset Curation
After searching extensively for an Alpaca-style dataset on Bhagvad Gita text, the best I could find was this. Others were either too small or completely irrelevant.
But the issue with this dataset was that it seemed incomplete, so I added appropriate texts to the input, instruction, output, & text columns. You can find and use the refined dataset here: refined_dataset.
Loading Model and Training Setup
I used the Unsloth framework to access and fine-tune the model. The framework uses much less hardware and is much more efficient and cost-effective. It helps with fast fine-tuning and inference by using way less memory.
Use this snippet to load your model using Unsloth:
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)Finetuning
I employ the classic parameter-efficient technique, LoRA, to make the process efficient and cost-effective. The majority of the model parameters are kept frozen to save memory and computation. Usually, only the attention and MLP layers are modified. Specify the values of the hyperparameters for the finetuning process carefully, which could make or break your product.
Here is a snippet as an example:
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
model_that_pissed_off_sam = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
trainer = SFTTrainer(
model=model_that_pissed_off_sam,
tokenizer=tokenizer,
train_dataset=train_dataset_dict["train"],
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)The process is a supervised finetuning process leveraging Unsloth optimizations to efficiently finetune the LLM. Choose the hardware parameters carefully based on your capacity, (but you don’t have to worry with Glows.ai, they have enough VRAM). BF16 is more stable for training if supported; otherwise, it falls back to FP16. Using the adamw_8bit optimizer helps with memory optimizing and gradient accumulation. For my case, I had ~42M trainable parameters.
SETTING UP THE GPU
Get done with the general steps:
- Sign up.
- Log in.
- Buy the amount of credits that is required; mine are test credits provided by Glows.ai — grateful :)
- Now, choose your instance as per your requirement.
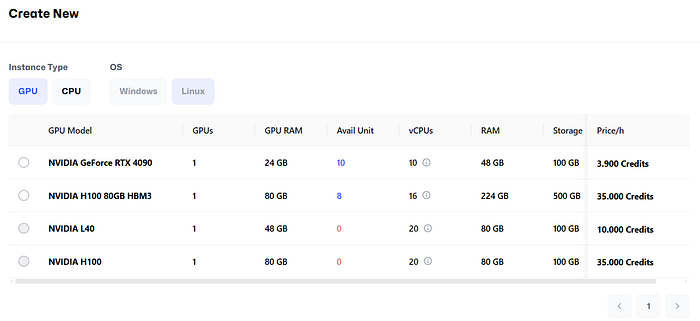
5. Choose your supported instance and complete checkout after deciding on the number of instances required. (Note that the credit usage starts right after the checkout is complete.)
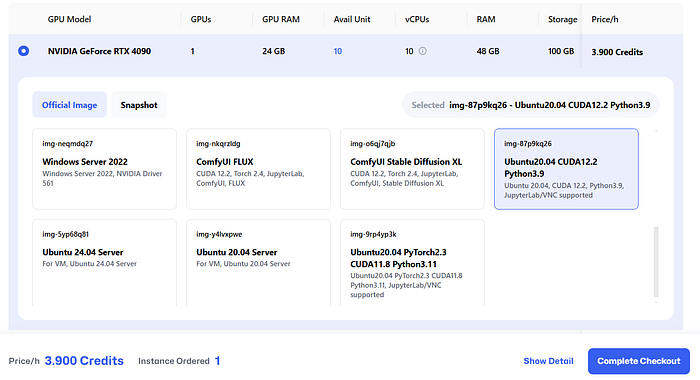
6. You can get access to the GPU backend by leveraging VNC ports, SSH, or HTTP ports. For this article, I’ll show a simple way to open Jupyter Lab from their console (good for beginners). Move to the HTTP port section and click on "Open.”
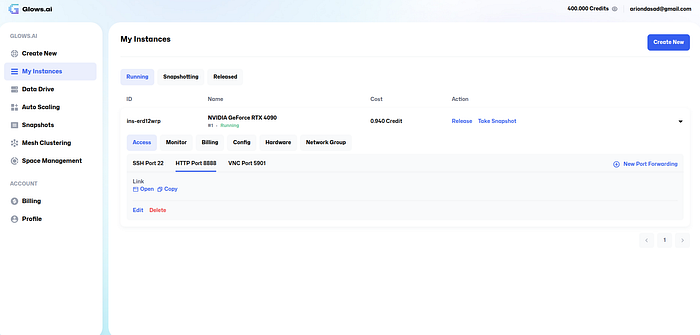
That’s it. You have your own workspace that runs on their GPU.
RUNNING YOUR NOTEBOOK
I would advise keeping the pipeline or Jupyter notebook prepared to immediately run it on the GPU to avoid eating up the credits trying to experiment.
- Upload your notebook. Run the cells.
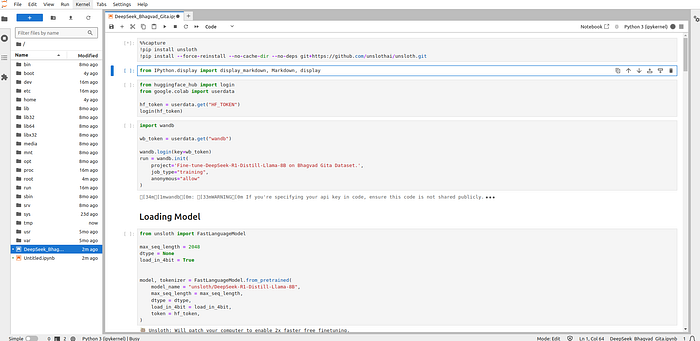
2. You can also monitor the GPU usage on the Glows AI page.

3. You can also login to W&B to monitor your finetuning process in real-time by visualizing their plots and analyzing the loss values during the model training.

4. Attaching some snapshots so that you can verify if your code is working fine.
Loading the model
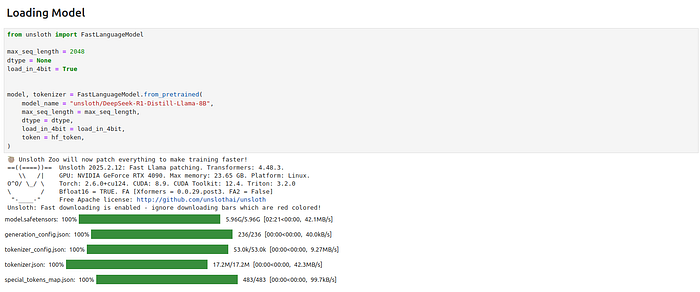
Downloading the dataset

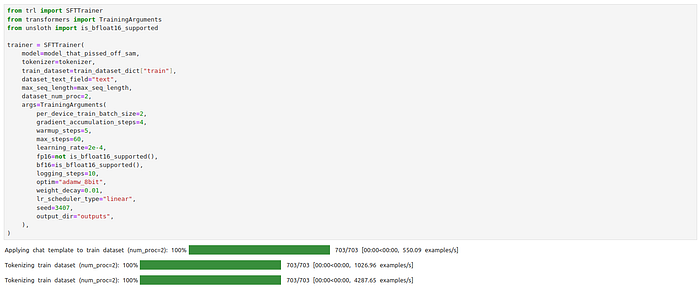
Supervised Fine Tuning script
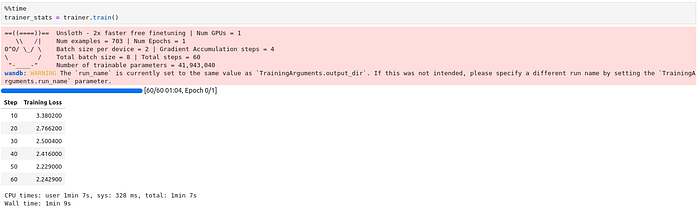
Training process (ignore the values; the dataset was not good enough)
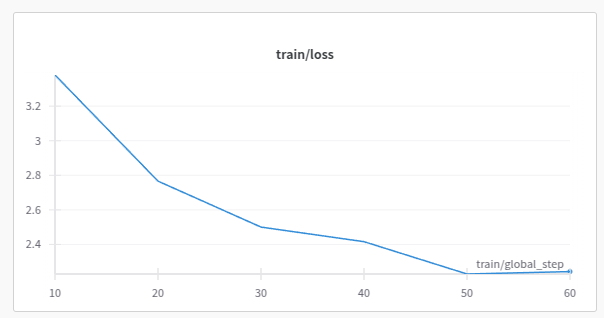
5. Go to W&B to check out the visualization plots.
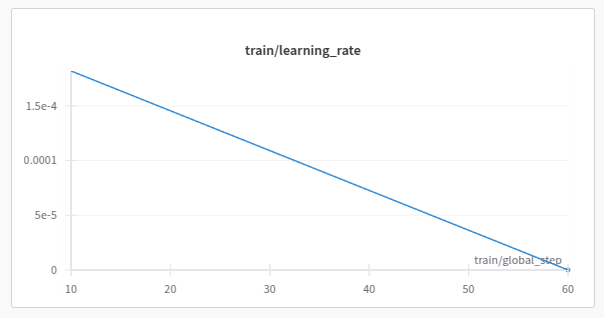
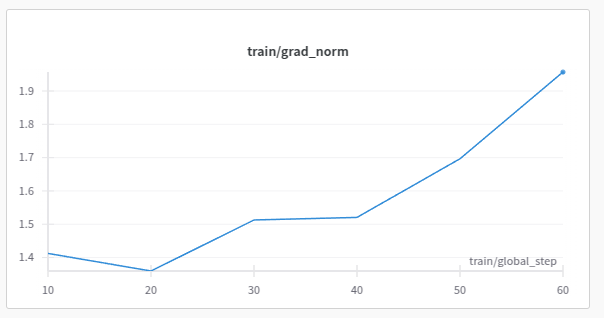
6. That’s it; you have successfully fine-tuned your model.
INFERENCE
Since we are using DeepSeek’s models, they will respond with their thinking process by default because they were trained that way. So, it’s better to shape the prompt template that way for the model to find it’s
mojo (might as well call it that).
Here’s my snippet:
inference_prompt_style = """You are an expert at Indian scriptures especially Bhagvad Gita.
You are supposed to that information to accurately answer the user's question.
### Question
{}
### Response
<think>"""
def infer_model(question) :
FastLanguageModel.for_inference(model)
inputs = tokenizer([inference_prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=300,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
return response[0]Here are some metrics to compare how the cloud GPU (NVIDIA GeForce RTX-4090 Ubuntu20.04 CUDA12.2 Python3.9) fared compared against the Colab TPU.
Training
Colab TPU : 340 seconds
Glows AI : 67 seconds
Inference
Colab TPU : 23.90 seconds
Glows AI : 11.08 seconds
I’m thankful to Glows.ai for providing me the credits to test their product.
